The structure of the DNA double-helix was published in 1953, but it took another 13 years to actually crack the genetic code.
The questions of how DNA is copied and codes for proteins remained for a while after the structure was confirmed.
The two key questions after the structure of DNA was figured out were:
1) How is it copied?
2) How does it code for proteins?
The first question was answered by Meselson and Stahl in 1958. DNA is copied ‘semi-conservatively’ - the old strands serve as a template for creating the new complementary strands.
The second question wasn’t fully resolved until 1966.
There, of course, were theories about how this occurred and Francis Crick gave a seminal lecture in 1957 (published as a paper in 1958), ‘On Protein Synthesis,’ which laid out the basic formula for how he believed this all worked.
He got it mostly right.
He proposed that there must be an 'adaptor' which carries the amino acids (we now call this transfer RNA, tRNA) to the template RNA (this became messenger RNA, mRNA) to synthesize the protein chain.
But Crick also hypothesized in this lecture that the genetic code is read 3 nucleotides at a time.
It was known that there were 20 amino acids and so Crick reasoned that since there are only 4 nucleotides in DNA and RNA, the ‘code’ for each amino acid couldn’t be 2 nucleotides (4x4) because that’s only 16 combinations, so optimally, it was a 3 nucleotide code (4x4x4) because that combination gave 64 possibilities - ~3 combinations for each of the 20 amino acids.
The first indication that Crick’s hypothesis was true came in 1961 when Nirenberg and Matthaei showed that an RNA sequence containing only U’s coded for poly-phenylalanine.
Inspired by this result, Crick showed that insertion or deletion of 1 or 2 bases causes proteins to become non-functional, but 3 base mutants still produce functional protein.
The code must be a triplet!
Nirenberg and Leder followed up in 1964 with triplet codes for a handful of amino acids but they frustratingly couldn't determine all of them.
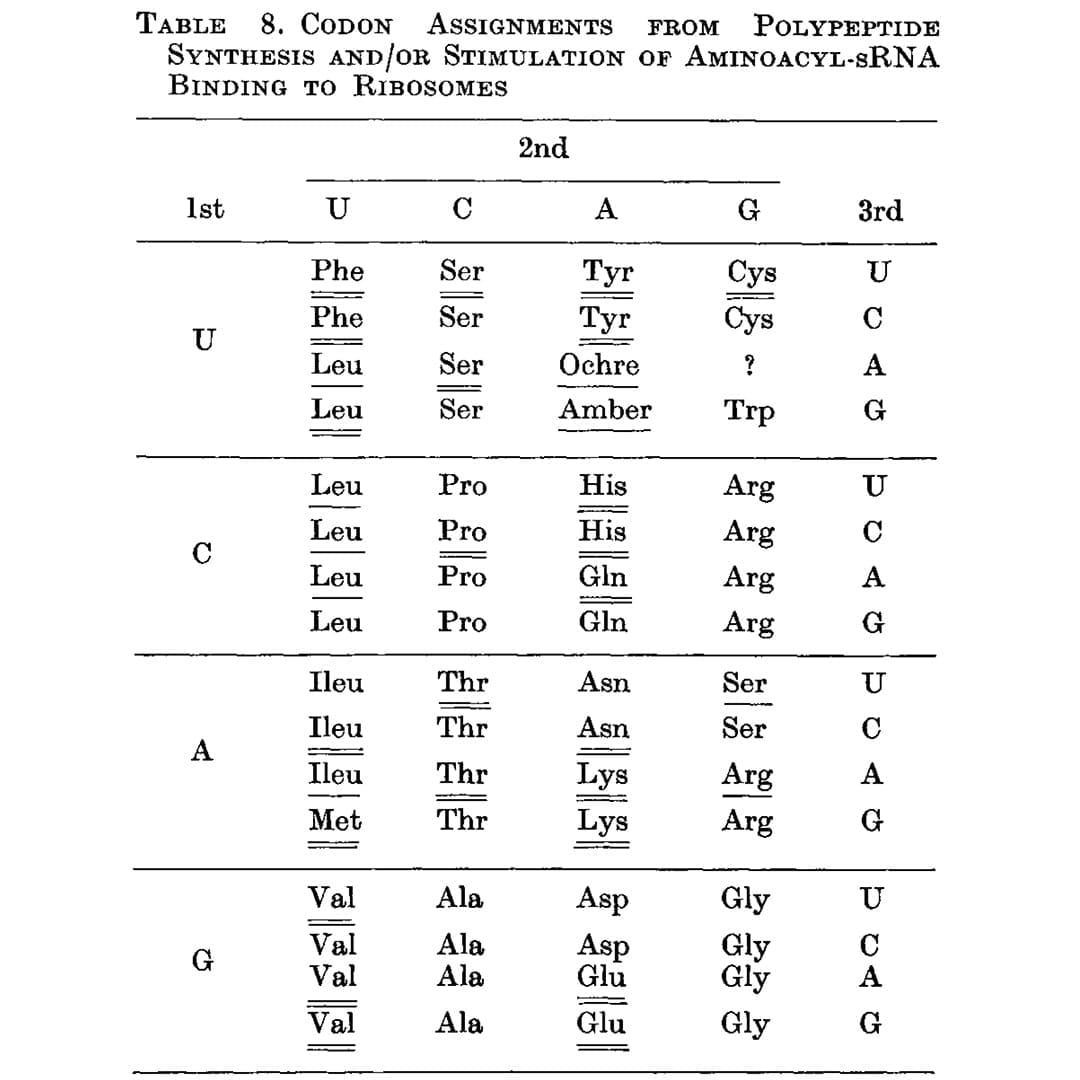
That problem was solved by Har Gobind Khorana, an Indian American scientist, whose work is the subject of the figure above.
While Nirenberg and team were using binding assays to try to capture the RNA-amino acid associations, Khorana approached it differently by synthesizing repeating dinucleotide and trinucleotide RNA polymers and seeing which amino acids ended up linked together in the resulting protein chain.
The outcome of this work can be seen below (underlines), and this is the first presentation of a nearly complete codon table. The only missing assignment is UGA, the third and final stop codon.
Unsurprisingly, Khorana, Nirenberg and Holley (he determined the structure of tRNA) shared the Nobel Prize in 1968 for deciphering how nucleic acids code for proteins.