Omic.ly Weekly 70
April 7, 2025
Hey There!
Thanks for spending part of your week with Omic.ly!
This Week's Headlines
1) Sequencing exomes in healthy populations pays dividends
2) Translation complicates the proteome, big time!
3) The Lac Operon showed us that gene expression can be regulated
Here's what you missed in this week's Premium Edition:
HOT TAKE: FDA has lost another battle in the war to regulate Lab Developed Tests, but its "never gonna give them up."
In a development that should surprise no one, population scale exome screening finds actionable variants.
When we completed the human genome project in 2003 it meant that genomics was basically over and scientists who did genomics had to pivot their careers to something else.
Unfortunately, that’s what happens when you complete things.
Kidding.
The Human Genome was only ~90% complete in 2003 (most of the coding genes were covered), and a gapless assembly of it wasn’t finished for another 19 years.
But even knowing where all of the genes in the human genome were located wasn’t super helpful.
We still had to figure out what they all did and how they contributed to health and disease.
And along the way, we realized that genetics is WAY more complicated than we thought!
This has meant that there’s been pretty good job security in genomics, because there’s still a lot of work to do to understand what’s going on here!
But that doesn’t mean we haven’t learned anything: we’ve been able to translate a bunch of those learnings into clinical practice.
We’ve identified hundreds of thousands of variants that lead to disease and are able to use genetic tools to detect these variants in people afflicted with genetic diseases.
Much of this testing, though, is reactive and relies on us seeing a phenotype or knowing that a patient has a family history of disease before we sequence them.
This is a very conservative approach to genetic testing and it means we miss a lot of diseases in people who don’t have (or don’t know they have!) a family history of disease or who are carriers of disease mutations but just aren’t showing symptoms yet!
What if we took a much less conservative approach and just sequenced anyone that wanted to be sequenced?
This might sound like a crazy idea, but sequencing is now cheap enough for us to do this at scale.
And at least one hospital system felt the same way!
Back in 2007, Geisinger health launched the MyCode project to biobank patient samples and link them to their EHR for future genetic analyses.
In 2014, they started a collaboration with the pharmaceutical company Regeneron to exome sequence all of the participants and return any Pathogenic/Likely Pathogenic (P/LP) results that were discovered in the sequencing process.
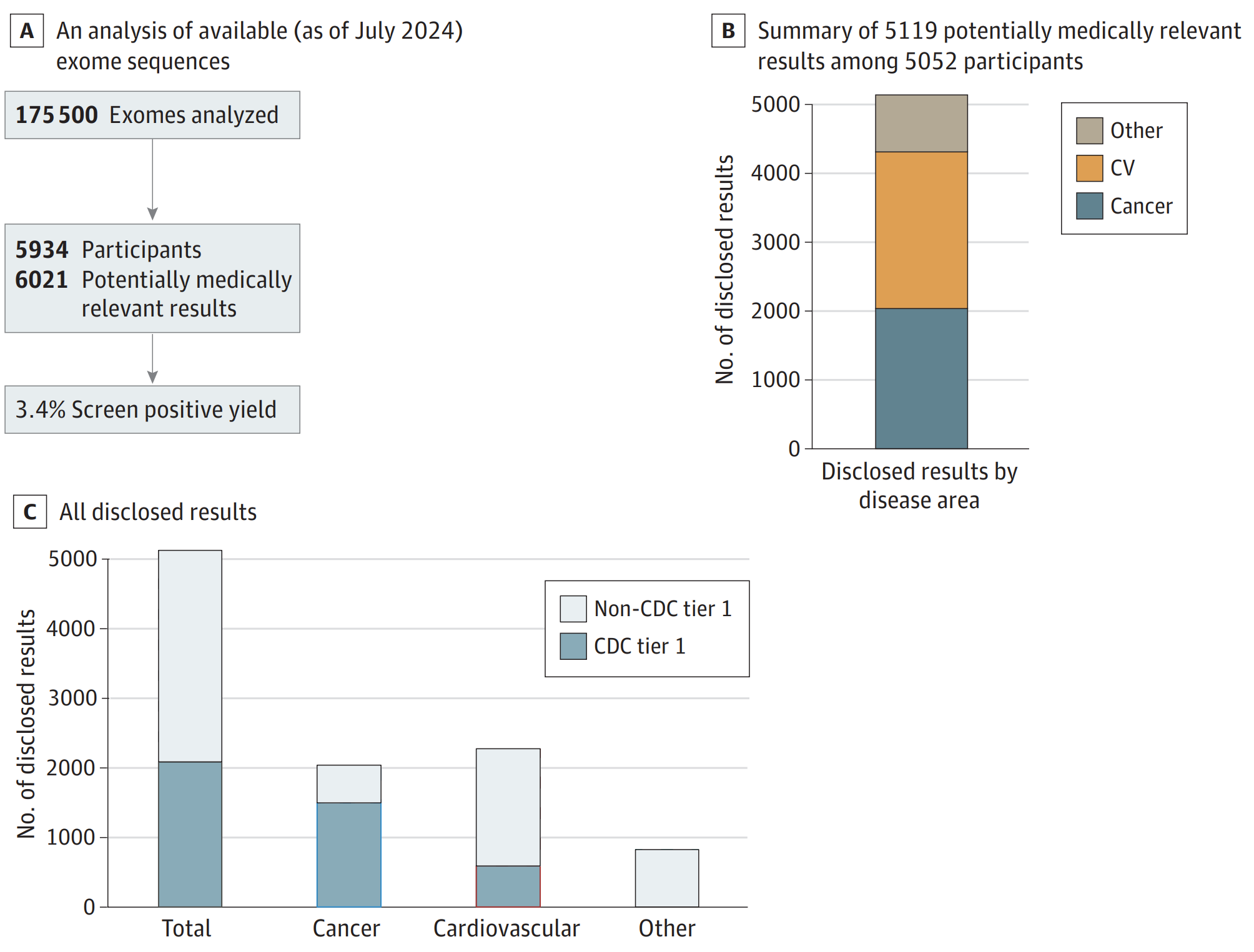
The results of this work can be seen in the figure above where A) 175,000 exomes have been sequenced and analyzed with a P/LP yield for 81 “actionable” genes of 3.4% B) of those results, the majority were related to risks for cardiovascular disease (CV) and Cancer and C) with about 1/3rd falling in CDC tier 1 targets (Hereditary Breast and Ovarian Cancer Syndrome, Lynch syndrome, and Familial hypercholesterolemia).
They also showed that ~90% of the people with a risk for developing disease were unaware they carried a disease causal mutation.
Now, you might be thinking that a yield of 3.4% might not sound like a lot, and if exomes now cost about $100 each to do this sort of analysis, it might not be worth it!
But when you consider we spend about $500B a year on cancer and cardiovascular disease treatments, exome sequencing everyone in the US (one time) for $300B might not be that bad of a deal after all.
And that’s especially true if patients, as they did in this study, make changes to help mitigate the risks of the pathogenic variants hiding in their genomes.
###
Savatt JM, et al. 2025. Genomic Screening at a Single Health System. JAMA Net Open. DOI:10.1001/jamanetworkopen.2025.0917
Translating the Proteome: There’s more to making proteins than just transcribing DNA into mRNA.
The biology 101 description of protein synthesis usually goes as follows:
RNA polymerase transcribes DNA into messenger RNA (mRNA).
mRNA is bound by a ribosome.
Bada bing, bada boom.
Protein!
Except, there’s a lot of stuff that happens in-between the creation of mRNA and the translation of that message by a ribosome.
And much like DNA transcription, there are MULTIPLE levels of regulation that occur on the cellular level to make sure that the right proteins are made at the right time!
With that in mind, it's also important to note that mRNA abundance is not directly correlated with protein abundance for approximately 30% of genes.
So, just having mRNA around doesn’t necessarily mean that a protein is going to be made!
What the heck is going on here?
Translation Initiation: This is the first and arguably most regulated step! For an mRNA to be translated it has to be found and bound by a ribosome. Except ribosomes aren’t just bouncing around the cytoplasm (or endoplasmic reticulum) looking for naked mRNAs! Ribosomes are actually recruited by other other factors like the cap binding protein complex eIF4F (eukaryotic translation initiation factors) and the Poly-A Binding Protein (PABP) that binds the mRNA tail. These two protein complexes circularize the mRNA. That way, when a ribosome gets to the end, it’s back at the beginning to start all over again! However, this circularization process is highly regulated and even when a ribosome does find its way to one of these RNAs, there’s no guarantee that it will actually be translated! The ribosome itself is regulated, and for it to start the process of scanning for the translation initiation codon (the start site) it must be bound by a methionine loaded tRNA!
Translation Elongation: This is the phase of translation where all of the amino acids are added to the growing protein chain. However, how quickly those amino acids are added can be regulated and this can affect how much protein is made from any one message!
Location, Location, Location: Whether an mRNA is translated into protein depends a lot on where it is! This makes sense and is an important factor in the regulation of translation. If an RNA is no longer needed, it can be bound by factors that bring it to a processing body (P-body) for decay. These are little areas within the cytoplasm where RNAs are decapped and chopped up by nucleases. But if a cell doesn’t want to destroy an RNA, it can save it for later by moving it to a stress granule (like a p-body, just with less chopping!). This usually happens during stressful situations and translation can be completed when conditions improve.
microRNAs: These are small pieces of RNA that bind to the 3’-UTR (Untranslated Region) of an mRNA and mark it for death by the RNA-induced Silencing Complex (RISC). If an RNA is disappeared, it can’t be translated!
'If gene expression determines the function of a cell, it must be important to control that process?' Yes, very! Let me tell you about the PaJaMo experiment.
Although we knew that DNA was the genetic material in the 1950s, there were still major questions about how DNA coded for protein and how that process, known as gene expression, was regulated.
While these were major questions at the time, an equally nagging question was whether enzymes (proteins) performed a specific function or if they could rearrange themselves to perform multiple functions.
There was a long standing hypothesis that enzymes were like little swiss army knives.
And they could be coaxed by environmental conditions to rearrange themselves to do different jobs depending on what was needed at the time.
A competing hypothesis argued that enzymes performed very specific functions and that it was actually the regulation of gene expression that determined how organisms responded to changes in their surroundings.
It was hypothesized that they did this by expressing different enzymes depending on what the current conditions required.
To settle this debate, Arthur Pardee, Francois Jacob, and Jacques Monod teamed up to study how bacteria are able to live and grow in the presence of multiple sugar sources.
It was known that E. coli could grow in the presence of both lactose and glucose and early work from Jacob showed that the 'lac' region of the bacterial genome seemed to control how they processed sugar.
This appeared to be the ideal system to suss out whether enzymes adapted to their conditions or if new enzymes were created to deal with whatever sugar was present.
Pardee, Jacob, and Monod (PaJaMo!) devised a series of experiments using bacteria that had different mutations (or combinations) in lac which contains 3 important regions:
z - makes beta-galactosidase, the enzyme that turns lactose into glucose and galactose
y - beta-galactosidase permease, the protein that brings lactose into the bacteria
i - inducer, a regulatory region that controls the expression of z and y
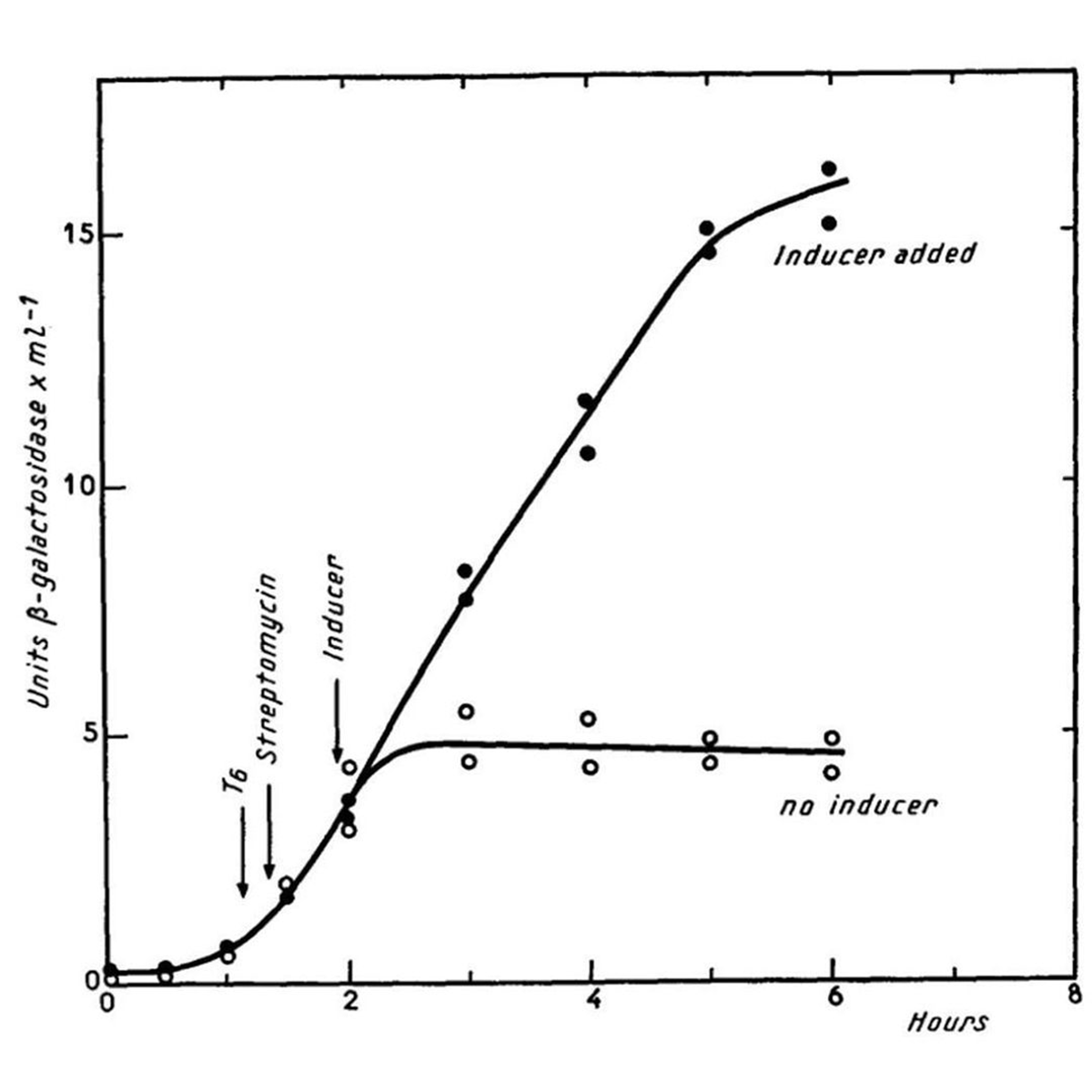
The figure above shows what happens in E. coli in the presence or absence of lactose (inducer).
When lactose is present (black dots) the bacteria make a lot of beta-galactosidase enzyme, when lactose isn't present (open dots) they don't make the enzyme.
Further research showed that the 'i' region is actually bound by a repressor protein that prevents the expression of z and y, and it's the binding of lactose to the repressor that releases this block!
While seemingly simple, the PaJaMo experiment unveiled what we now call the 'lac operon.'
It provided our first evidence that enzymes perform a specific function and that gene expression can be regulated to determine which enzymes are active at any given time!
###
Pardee AB et al. 1959. The genetic control and cytoplasmic expression of “Inducibility” in the synthesis of β-galactosidase by E. coli. JMB. DOI: 10.1016/S0022-2836(59)80045-0
Were you forwarded this newsletter?
LOVE IT.
If you liked what you read, consider signing up for your own subscription here: